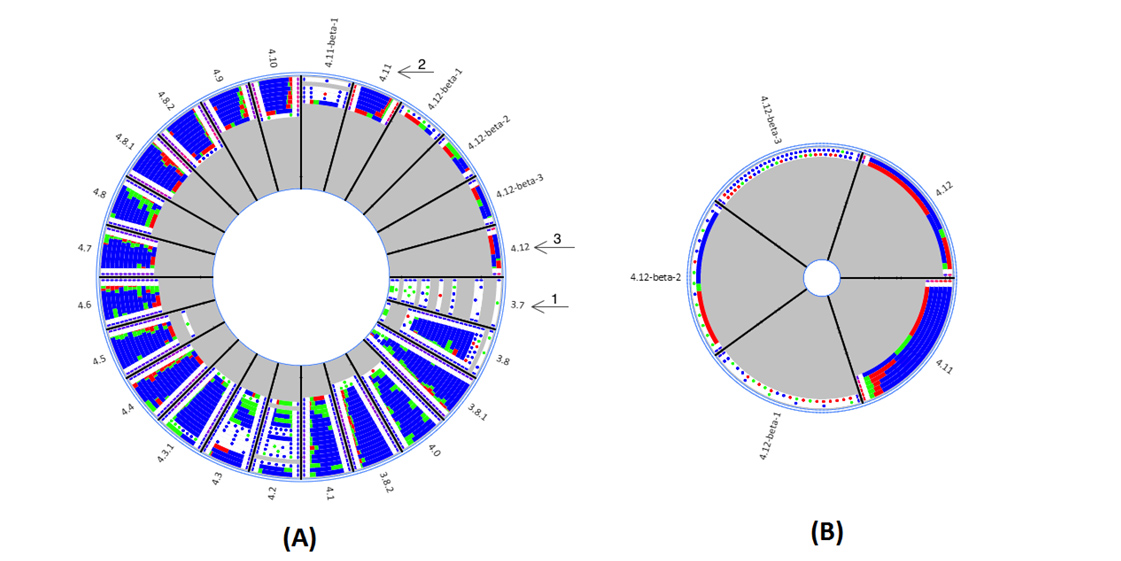
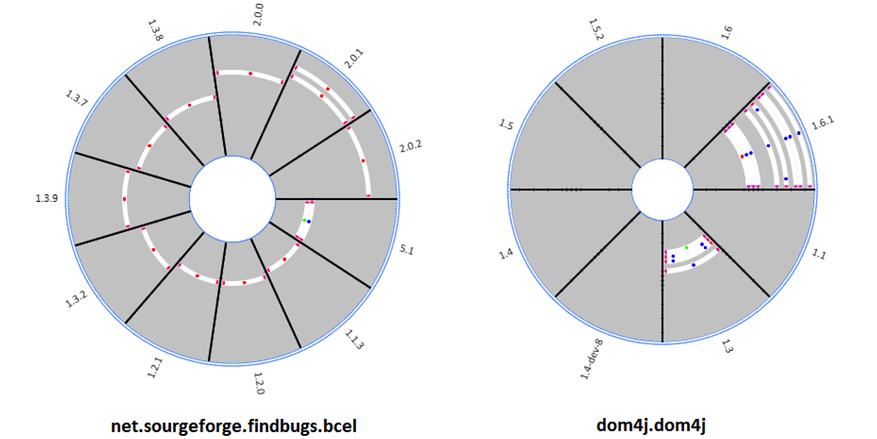
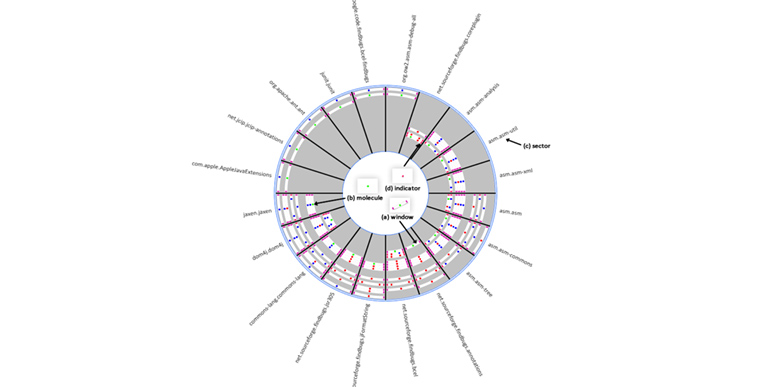
Software evolution produces a large amount of data. Software en- gineers may benefit from these data while carrying out daily activities. The challenge is to understand all the data and recovery valuable information. One of these activities is to maintain library dependencies of a project. This is a complex task, since it is usual a system and its library dependencies evolving separately. It is necessary to be careful when updating the libraries of a project. The maintainers need to know the history about a system’s past upgrade decisions and which dependencies were adopted at the same time. Software Evolution Visualization (SEV) can be a promising approach to this end.
Libraries are collections of components that solve certain recurring problems. Each of these problems is from a certain domain. Examples for such library domains include Graphical User Interfaces (GUI), database access, logging, XML parsing, communication, etc. Specially in the Java programming language, libraries are used quite intensively. The Java 6 runtime environment (JRE) alone contains about 16,000 classes, and there are thousands of 3rd party libraries available for many different purposes [Quante 2008].
Aspects of Implementation: Evowave architecture is designed to be simple and extensible. The client side uses a well known Javascript framework called ProcessingJS [ProcessingJS 2015], which is used to draw the visualization. The metadata used by it is defined in a key-value notation called JSON (Javascript Object Notation). The JSON has all the data needed by the visualization to depict the data following the metaphor’s concept. This data is collected by the server according to the period defined. The client will never ask extra data from the server as long as the client does not change the period of analysis. The nature of this tool is to consume services that returns all the information needed to perform an action. Thus, in the server’s side, a servlet that fulfill the RESTful architecture was used. Every service provided by the server returns the data according to the visualization metadata. More details on the algorithms used can be found in [Magnavita 2016].